
Blogs, Artículos, Cursos, Programas, Certificaciones relacionados con Big Data
¿Qué es Big Data?
Big Data son activos de gran volumen, alta velocidad y/o alta variedad de información estructurada y no estructurada que requieren nuevas formas de procesamiento para permitir descubrir patrones en dicha información, que permitan mejorar en la toma de decisiones y optimizar los procesos dentro de las organizaciones.
El desafío del Big Data consiste en buscar, capturar, almacenar, compartir, analizar y agregar valor a los datos con los que cuenta una organización; información que en su momento era inaccesible. No es relevante el volumen de datos o su naturaleza, lo que importa es su valor potencial que sólo las nuevas tecnologías especializadas en Big Data pueden explotar, brindando beneficios como la mejora en el proceso de toma de decisiones.
Cursos, Programas, Certificaciones




Blog

Apache Spark: Flexibilidad y Procesamiento en Big Data
Este blog explica las funciónes de Apache Spark, flexibilidad y compatibilidad de esta herramienta Big Data de análisis de datos a gran escala.
White Papers
¿Qué es Big Data?

¿Qué es Apache Hadoop?

¿Qué es Apache Spark?

CRISP-DM: Una Metodología para Proyectos de Data Mining

Desarrollo de Aplicaciones Interactivas con Shiny

Casos de Éxito en Big Data

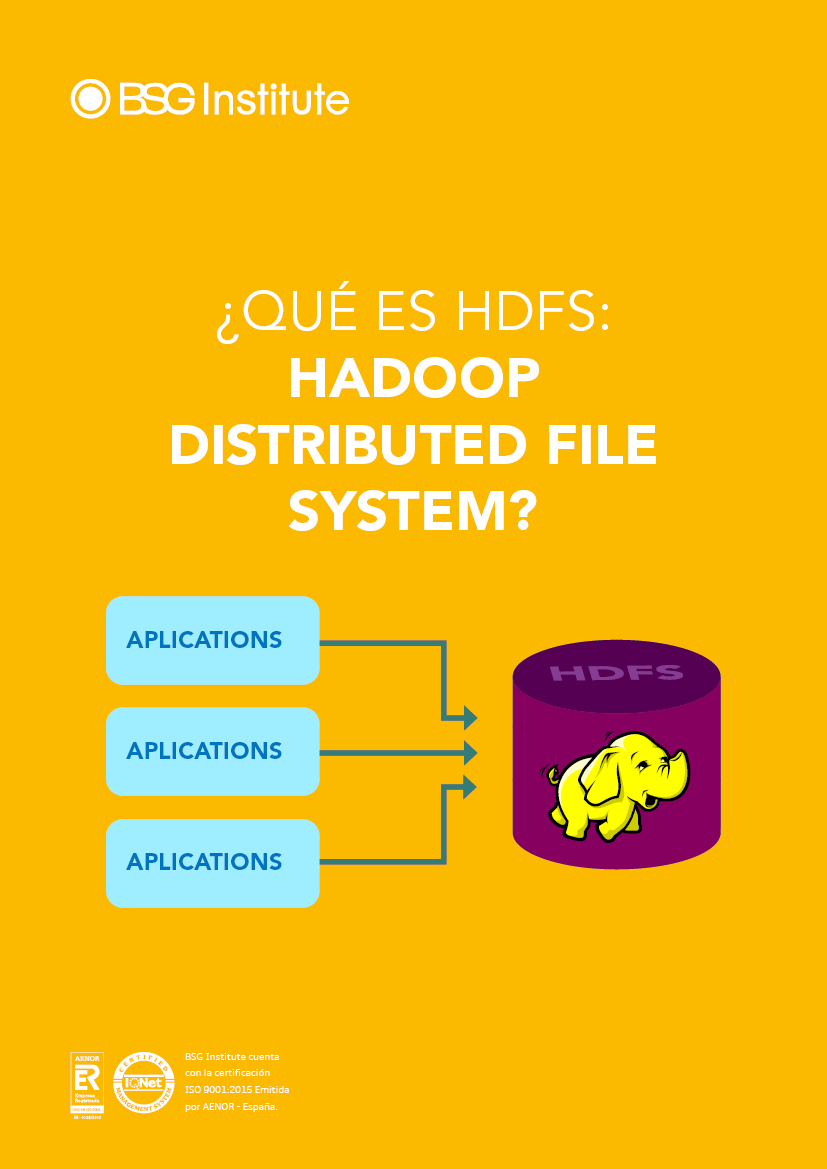
¿Qué es HDFS: Hadoop Distributed File System?
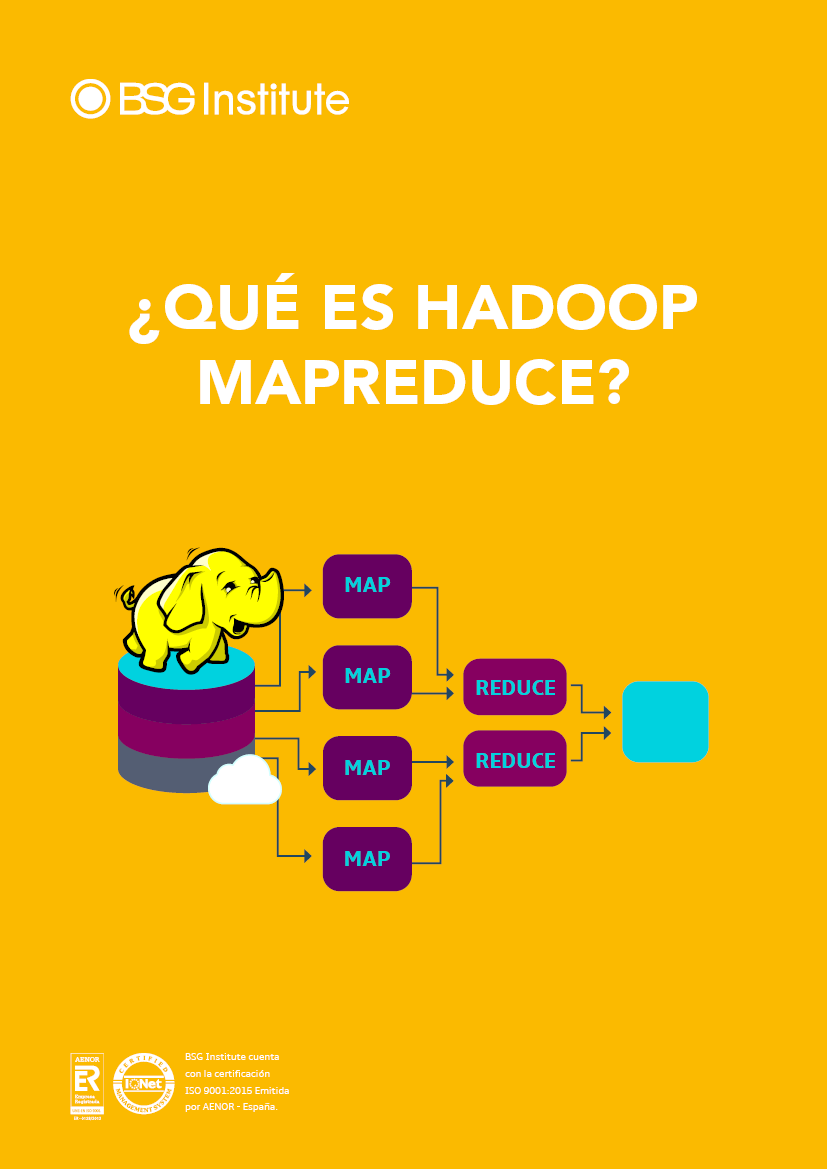
¿Qué es Hadoop MapReduce?
¿Qué son los Árboles de Decisión en Machine Learning?

¿Qué es el Clustering en Machine Learning?

¿Qué es el Análisis de Regresión en Machine Learning?

¿Qué es el Aprendizaje Supervisado y No Supervisado en Machine Learning?

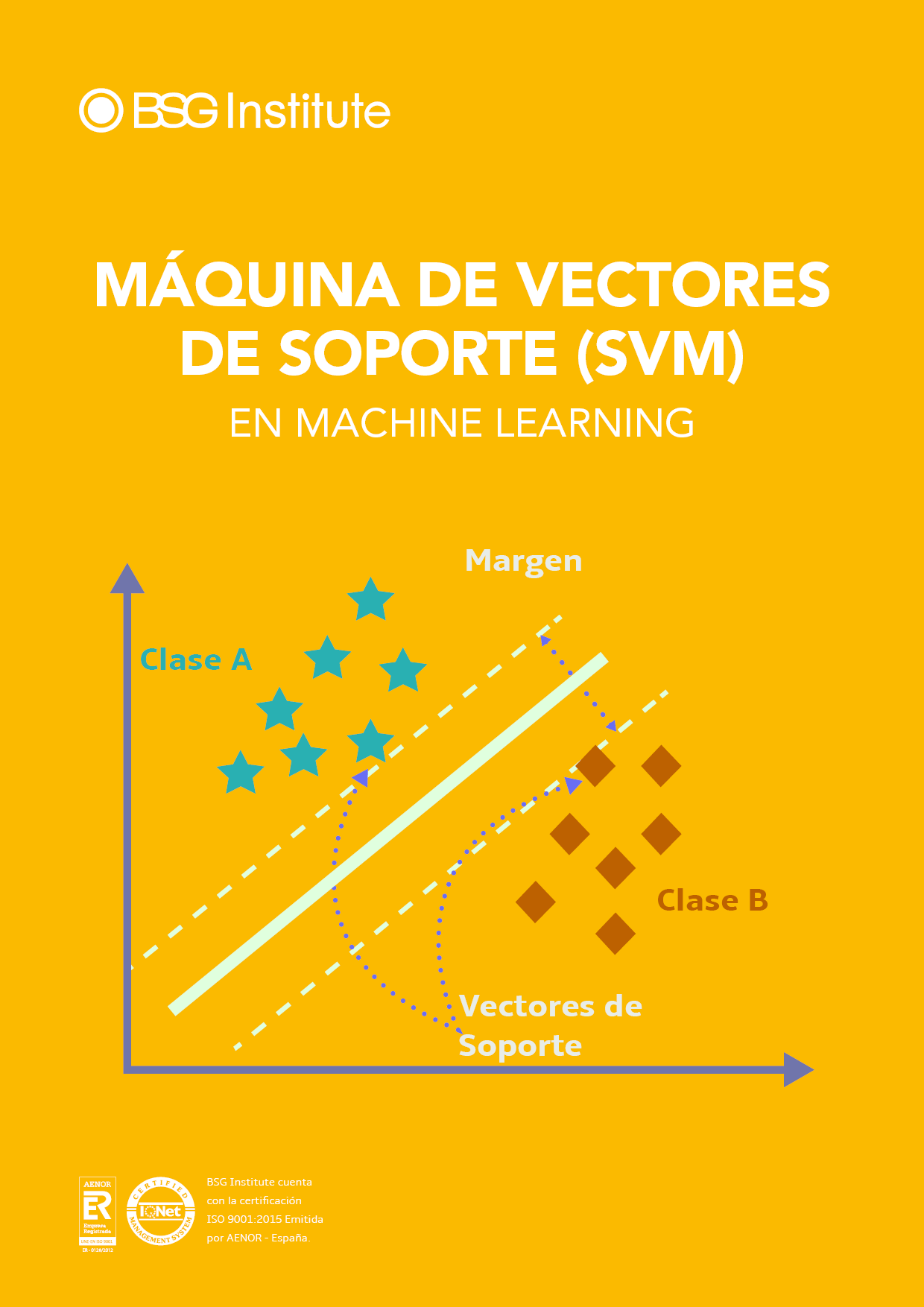
Máquina de Vectores de Soporte (SVM) en Machine Learning
¿Qué es el Modelamiento por Uplift en Machine Learning?

¿Qué son las Redes Neuronales Artificiales?

Machine Learning y Data Mining

¿En qué consiste el Text Mining en Machine Learning?

Python y R enfocados al Desarrollo de Aplicaciones Big Data

Métricas para evaluar Modelos Predictivos: Curvas Lift y ROC
Herramientas de Apache Hadoop: PIG, Hive y Flume

Central Telefónica
Más Información
The PMI® Authorized Training Partner seal, PMI logo, Project Management Professional (PMP), Certified Associate in Project Management (CAPM), PMBOK, are registered marks of the Project Management Institute, Inc.